
Im Rahmen seiner Bachelorarbeit hat Andreas das Thema „Analyse der Named Entity Recognition des KI-Modells BERT in einer spezifischen Sprachdomäne“ erfolgreich behandelt. Natürlich möchten wir euch dieses spannende Thema rund um die Spracherkennung mit Künstlicher Intelligenz nicht vorenthalten! Andreas bleibt auch nach seinem Abschluss bei uns und unterstützt das Team weiterhin als Fullstack Entwickler.
Viele werden es kennen, lange wird nach einem bestimmten Dokument im digitalen Chaos seines Rechners gesucht. Ähnlich ergeht es einigen Mitarbeitern in Unternehmen, wenn sie bespielsweise auf der Suche nach Dokumenten von Kollegen sind. Häufig ist der Inhalt nur wage bekannt, nicht aber der explizite Dateiname. Intelligente Suchsysteme können bei diesem Anliegen helfen, indem Dokumente nicht nur anhand des Dateinamen, der Überschrift oder über Schlagwörter indexiert werden, sondern auch der thematische Kontext eine entscheidende Rolle spielt. Immer häufiger unterstützt zu diesem Zweck die sogenannte Named Entitiy Recognition (NER) bei der Klassifizierung von Dokumenten und der Suchmaschienenoptimierung. Der Nutzen dieser semantischen Analyseform wird besonders bei mehrdeutigen Wörtern deutlich. Als Beispiel dient das Wort „Bank“, im einzelnen betrachtet, nicht direkt zwischen den Entitäten Geldinstitut und Sitzgelegenheit unterscheidbar. Bei der semantischen Analyse der NER wird die eindeutige Entität anhand von dem angrenzenden Kontext eines Nomens bzw. einer Nominalphrase bestimmt und einer Kategorie zugewiesen. Für das Wort „Bank“ in Form eines Geldinstituts würde z.B die Kategorie „Organisation“ passen.

Heutzutage wird für die NER vermehrt auf vortrainierte Sprachmodelle durch Deep Learning zurückgegriffen. Diese werden auf eine bestimmte sprachliche Erkennungsaufgabe z.B. der NER mit einer zweiten Trainingsphase abgestimmt. Das sogenannte Fine Tuning benötigt wesentlich weniger Rechenzeit und zusätzlich gegenüber den Pre Training deutlich weniger Daten. Beim Fine Tuning handelt es sich hierbei um ein supervised Training, d.h. die Trainingsdaten benötigen ein Label über das gewünschte Ergebnis. Anhand der Labels soll das Modell während der Trainingsphase den Zusammenhang zwischen den Trainingsdaten und dem gewünschten Ergebnis, in Form der Labels, erlernen. Das umfangreichere Pre Training verwendet hingegen als ein unsupervised Training in den Trainingsdaten keine Labels. Ziel der Bachelorarbeit war, das Verbesserungspotenzial von ausgewählten Trainingsdaten auf einen bestimmten Anwendungsfall zu analysieren. Zu diesem Zweck wurde das von Google vortrainierte Sprachmodell BERT, als Ausgangspunkt für zwei Fine Tunings mit einer anschließenden Gegenüberstellung der beiden feinabgestimmten Modelle ausgewählt.

Konkret sollte dabei die folgende Hypothese anhand der Bachelorarbeit überprüft werden: BERT feinabgestimmt mit domänenspezifischen Trainingsdaten erzielt eine bessere Erkennungsrate von Entitäten in der gleichen Sprachdomäne, als das zweite, feinabgestimmte Modell mit Trainingsdaten aus einer allgemeinen Sprachdomäne. In einem Experiment wurden dafür zwei feinabgestimmte BERT Modelle mit den gleichen zufälligen Testdaten aus der Sprachdomäne Musik evaluiert. Für eines der beiden vortrainierten BERT Modelle wurden auch für das Fine Tuning, die Trainingsdaten aus dem sprachlichen Kontext Musik gewählt. Im Unterschied dazu verwendete das Vergleichsmodell Trainingsdaten aus Zeitungsartikeln im Fine Tuning.
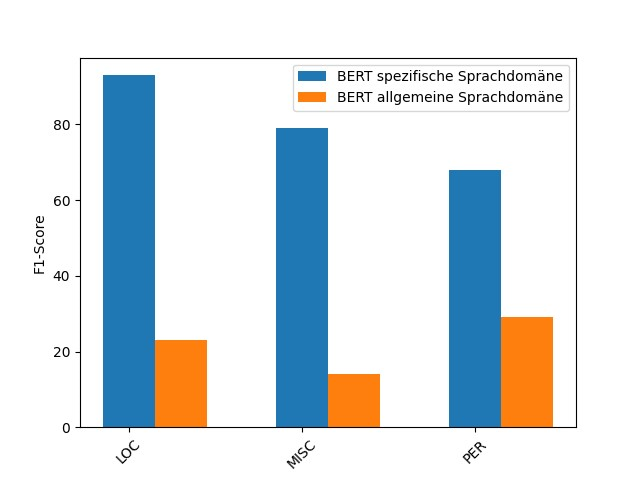
Der Vergleich beider Modelle mit den Testdaten konnte die zuvor aufgestellte Hypothese bestätigen. BERT feinabgestimmt mit den domänenspezifischen Trainingsdaten erzielte in allen Entitätskategorien einen höheren F1-Score. Es lohnt sich also für ein Fine Tuning auf die NER in einem spezifischen Sprachkontext, speziell dafür ausgelegte Trainingsdaten zu verwenden. Im Sprachkontext der Musik können schließlich Wörter ebenfalls eine andere Bedeutung aufweisen wie z.B das Wort „Rock“.
Wir gratulieren ihm herzlich zur bestandenen Abschlussarbeit!