
Bei diesem Projekt ging es um die Einführung eines Mitarbeiterportals mit Standorten in mehreren Ländern und vielen verschiedenen Bereichen.
Zum Portal gehörten diverse Applikationen, z.B
- Eine unternehmensweite Suche von Adressen und Kontakten
- Ein Dokumentenmanagementsystem zur dokumentenbasierten Zusammenarbeit
- Diskussionsforen für die Interaktion der Mitarbeiter
- Mediathek für Video- und Audio-Dateien
- Wissensbibliothek auf Basis eines Wiki
-
Redaktionell gepflegte Unternehmensnews
Aufgrund des Umfanges wurde der Livegang in mehreren Schritten durchgeführt.
Zuerst wurde den Mitarbeitern nur der Bereich der Diskussionsforen als Option zur Verfügung gestellt, während beim letzten Kundenrelease jeder Nutzer automatisch auf die neue Umgebung geleitet wurde.
Vor jedem Livegang fand eine Kommunikationskampagne statt, in der die zukünftigen User und alle beteiligten Fachbereiche rechtzeitig und umfassend informiert wurden. Dazu gehörte unter anderem der geplante Einführungszeitpunkt, eine Gebrauchsanweisung und eine Übersicht der Verbesserungen und Neuerungen.
Jede Kampagne diente einerseits dazu die Mitarbeiter an das neue Portal heranzuführen und es bekannt zu machen. So wurde bei den Mitarbeitern die Akzeptanz für das neue Tool bereits im Voraus erhöht und die Neugier darauf geweckt. Andererseits hatten die teilnehmenden Fachbereiche durch die Kampagne die Möglichkeit die notwendigen externen Systeme getestet und zeitgerecht zum Livegang zur Verfügung zu stellen. Die Effizienz der Kommunikation wurde durch einen zentralen Ansprechpartner beim Kunden, der auch auf Managementebene Informationen entgegennahm, weiterleitete und Entscheidungsvorlagen lieferte, erhöht.
Während der Entwicklung des neuen Portals wurde in realitätsnahen Tests regelmäßig geprüft, ob das System zur Einführung bereit ist. Diese Tests fanden über den gesamten Zeitraum der Entwicklung statt mit dem Ziel, Fehler und Schwachstellen im Voraus zu identifizieren und zu beheben. In der Testphase fand zu jedem Zeitpunkt ein Austausch zwischen allen beteiligten Fachbereichen statt.
Auswertungen der Benutzerzugriffe aus dem bestehenden Portal erlaubten Rückschlüsse auf das Anwenderverhalten und unterstützen die Abschätzung der technischen Anforderungen an die neue Basis. Auf diese Weise wurde sichergestellt, dass das System den Livegang schaffen kann.
Im Verlauf der Entwicklung stellte sich heraus, dass die Überwachung des Systems in zu großen Zeitabständen erfolgt. Teilweise wurden nur alle 15 Minuten Telemetriedaten wie Speichernutzung und CPU-Auslastung ermittelt. Was für einen kontinuierlichen Betrieb eines langjährig genutzten und erprobten Systems ausreichen mag, ist unzureichend für die Überwachung eines komplett neu entwickelten Systems. Insbesondere an den Tagen der initialen Bereitstellung, an denen viele Unbekannte das Gesamtverhalten beeinflussen: Wie werden die Anwender die neue Lösung annehmen und nutzen. Wie sieht das tatsächliche Anwenderverhalten aus? Wie verhält sich das stärker verteilt aufgebaute System unter Last? Wurden evtl. Probleme und Flaschenhälse übersehen? Damit auf Probleme umgehend reagiert werden kann, die während des Liveganges auftreten können, muss eine feingranulare Beobachtbarkeit des Systems gewährleistet sein. Nur so können Probleme kurzfristig erkannt und adressiert werden.
Für ein genaueres Monitoring nutzten wir als Basis die Open-Source-Software Riemann. Riemann verfolgt einen Push-Ansatz, d.h. Sensordaten werden von den Clients zum zentralen Riemannserver gepusht. Mit Hilfe der Riemann-Client-Bibliotheken, die für unterschiedliche Programmiersprachen verfügbar sind, ist die Entwicklung von Push-Clients sehr flexibel. Wir setzten auf Groovy als Programmiersprache und programmierten einige kleinere Skripte, die quellspezifisch Daten erfassten, diese Daten in eine einheitliche Struktur brachten und über die Riemann-Bibliothek übers Netzwerk schickten. So brachten wir Überwachungsskripte für die zentrale SSO-Komponente und einige Maschinenwerte in Stellung. Alle Benutzeranfragen passieren die zentrale SSO-Komponente, so dass sich daraus ein gutes Verständnis der Verwendung des Gesamtsystems ableiten ließ. Als Metrikquellen griffen wir auf Statistikinformationen zurück, die diese SSO-Komponente ohnehin bereitstellte, die jedoch im bisherigen Betrieb nicht abgefragt wurden.
Der zentrale Riemann-Prozess nimmt die Metriknachrichten entgegen und kann über sein mächtiges Stream-Konzept Filterungen und Aggregationen vornehmen. Die Konfiguration des Riemann-Servers besteht im Kern aus einem Clojure-Programm, das die Verarbeitung mit den Streams-Abstraktionen funktional beschreibt. Die funktionale Herangehensweise bereitete initial etwas Irritationen, speziell bei imperativ geprägten Programmierern, offenbarte bei etwas längerer Beschäftigung jedoch enormes Potential.
Ein einfaches Dashboard, das direkt auf die Streams-Daten aufsetzte, ermöglichte die visuelle Darstellung der wichtigen Erkenntnisse aus den Metrikdaten und damit einen feingranulareren Einblick in den aktuellen Zustand des Systems. Es sollte uns sehr nützlich beim Livegang sein.
Eine Schwachstelle konnten wir im Vorfeld im SSO-System mit dem Toolset identifizieren. Die zentrale Komponente für die Authentifizierung und Zugangsautorisierung zeigte in Lasttests, bei steigenden, konkurrierenden Zugriffen ein Problem in der individuell für den Kunden entwickelten zertifikatsbasierten Authentifizierung. Eine Race-Condition in der multi-threaded Programmierung zur CRL-Überprüfung führte zu Abstürzen des Gesamtprozesses und damit zum schlagartigen Verlust aller darauf befindlichen Benutzersessions.
„Lieber einmal zu viel als einmal zu wenig“ ist nur eine Redensart von vielen, die redundante Systeme erklärt. Einfach gesagt, man vervielfacht Systeme in der Infrastruktur, um die Auswirkungen von technischen Defekten oder gar eines Gesamtausfalls zu minimieren. Aus den genannten Problemen in der SSO-Komponente, die leider nicht kurzfristig behoben werden konnten, wurde diese auf vier virtuellen Maschinen (VM) installiert und so parallel genutzt. Diese Maßnahme sollte den „blast radius“ eines Ausfalls dieser Komponente minimieren. Das wäre weder aufgrund der Speichernutzung noch der CPU-Auslastung nötig gewesen. Im Gegenteil, die VMs langweilten sich im Betrieb.
Beim Livegang wird das Systemverhalten ständig beobachtet mit dem Ziel, Probleme früh zu erkennen und zu beheben. Durch eine effektive und effiziente Kommunikationsweise konnten Fehlermeldungen während des Liveganges des Mitarbeiterportals identifiziert, übermittelt und behoben werden.
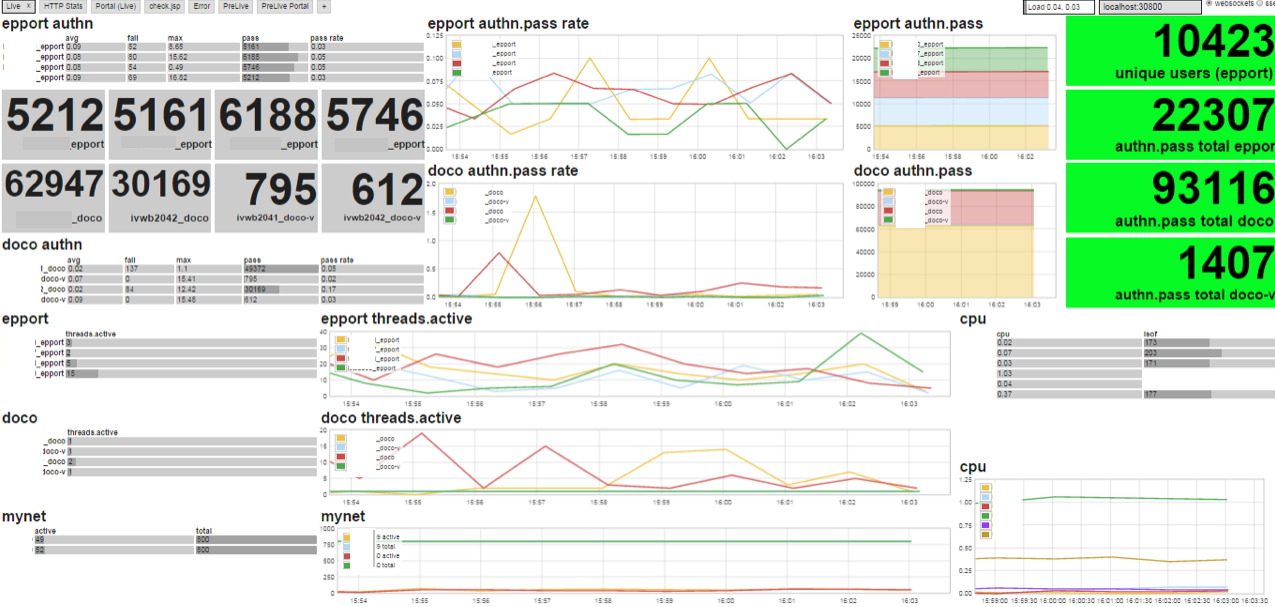
Dafür wurde am Tag des Liveganges ein Zusammentreffen der beteiligten Personen im „Livegang War Room“ organisiert. Die Hauptverantwortlichen des Projektes befanden sich in der Mitte des Raumes und die Verantwortlichen für die Komponenten auf Fachebene am Rand. Hier hatten alle das Dashboard und die gemeinsame Tafel mit allen wesentlichen Informationen im Blick. Gerade in der Anlaufphase eines neuen Systems ist „Leute, die auf Dashboards starren“ adequat und sinnvoll. Jeder Komponentenverantwortliche hatte ein bis zwei Entwickler im Hintergrund, die gezielt und kurzfristig auf Probleme reagieren konnten.
Ziel während eines Livegangs ist es, Probleme zu erkennen und zu beheben, bevor der Anwender des Systems etwas davon bemerkt. Im Verlauf des letzten und umfangreichsten Liveganges des Mitarbeiterportals stellte sich relativ früh heraus, dass die CPU-Kapazität für die hohe Anzahl von Anfragen nicht ausreichend war. Verstärkt wurde das, weil zusätzlich als Puffer vorgesehene Kapazitäten zunächst nicht zur Verfügung standen. In dieser hektischen Phase mussten die Verantwortlichen auch beruhigend auf die Beteiligten einwirken, die einen Ausfall des Systems befürchteten.
Durch die Virtualisierung der Hardware konnten die fehlenden Kapazitäten jedoch schnell bereitgestellt werden. Eine Konfigurationsänderung und ein folgender rolling-restart der fraglichen VMs und dem weiteren Verlauf des Livegangs konnte beruhigt und wohl beobachtet entgegen gesehen werden.
Zusammenfassend lässt sich feststellen, dass bei jedem Livegang folgende Punkte zu beachten sind:
- Neue und insbesondere umfangreiche Systeme sollten schrittweise in mehreren Livegängen eingeführt werden.
- Die Anwender sollten, falls möglich, gruppenweise Zugang erhalten.
- Durchführung von Tests über den gesamten Entwicklungszeitraum. Diese sollten möglichst nah an der Realität sein.
- Vor der finalen Bereitstellung müssen alle identifizierten Fehler und Schwachstellen beseitigt sein.
- Alle externen Systeme müssen zum Zeitpunkt des Liveganges zur Verfügung stehen.
- Nutzung virtueller Maschinen oder Cloud-Umgebungen. Sie ermöglichen schnelle Reaktionen bei Kapazitätsproblemen.
- Redundante Systeme verringern die Wahrscheinlichkeit eines Gesamtausfalls.
- Vor und während eines Liveganges sind die Kommunikation und der Informationsaustausch entscheidende Faktoren.